Fraud Detection
Summary
This Jupyter notebook focuses on building a machine learning model to detect fraudulent credit card transactions using the XGBoost algorithm. The project utilizes a fictional dataset designed to simulate real-life transaction details, sourced from Kaggle. The goal is to enable credit card companies to identify unauthorized transactions effectively, ensuring customers are not charged for purchases they did not make.
The notebook is structured into several key sections:
- Import Packages and Checking Data: Initial setup includes importing necessary libraries and checking the dataset for missing values and correct data types.
- Data Preprocessing: Handling categorical data, feature engineering, and preparing data for modeling.
- Model Building: Developing the fraud detection model using the XGBoost framework.
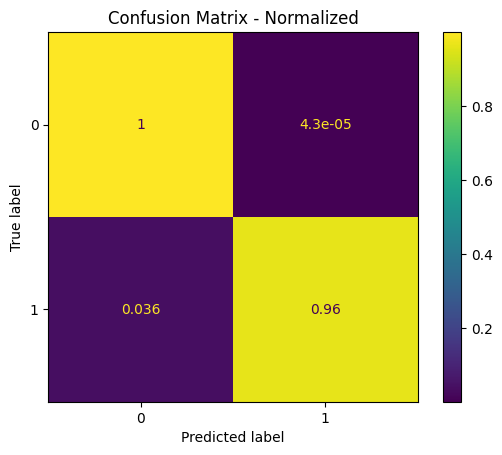
- Model Evaluation: Evaluating the model’s performance with appropriate metrics.
- Conclusion: Summarizing the findings and suggesting further improvements or additional analyses.
Techniques
The analysis employs various data science and machine learning techniques:
- Data Cleaning: Ensures the dataset has no missing values and all data types are correctly set for analysis.
- Exploratory Data Analysis (EDA): Uses libraries like Matplotlib and Seaborn for visual exploration of the dataset, helping to understand patterns and anomalies.
- Feature Engineering: Enhances model performance by creating new features that help in distinguishing fraudulent transactions.
- Machine Learning Modeling: Utilizes the XGBoost algorithm, known for its performance in classification tasks, to predict fraudulent activities.
- Model Evaluation: Applies metrics like accuracy, precision, recall, and F1-score to measure the effectiveness of the model.
This project is implemented using Python, with extensive use of libraries such as pandas for data manipulation, Matplotlib and Seaborn for visualization, and XGBoost for machine learning modeling.